אימון יעיל של מודלי שפה של DeepSeek והשפעתו הפוטנציאלית
מאחר שכמעט כל משקיע שלנו פנה אלינו ושאל מה זה DeepSeek ומה ההשפעות הפוטנציאליות שלו על התיק שלנו, חשבנו שהכי טוב יהיה להכין מדריך קצר (מאוד) עם המחשבות הראשוניות והתגובה שלנו.
מה זה DeepSeek?
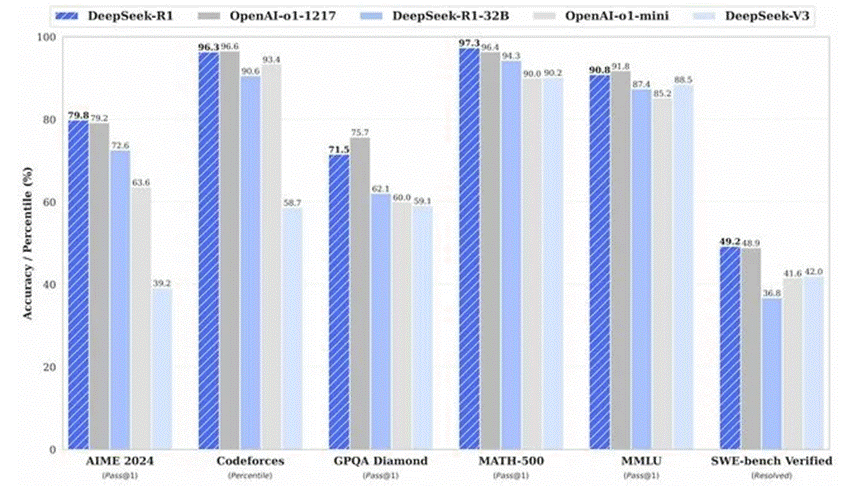
באופן מדהים, DeepSeek נוסדה לפני פחות מ-3 שנים וזו חברת סטארט-אפ סינית בתחום הבינה המלאכותית שמאמנת מודלי שפה גדולים (LLM) וזכתה לתשומת לב רבה בזכות המודל שלה שהשיג ביצועים תחרותיים בהשוואה למודלים מובילים של חברות אמריקאיות גדולות כמו ChatGPT, Gemini ו-Anthropic.גם אם אנחנו מניחים ש-DeepSeek תיפלו קצת עם חלק מהנתונים שלהם (כלומר, עלויות אמיתיות), הם עדיין הצליחו להשיג ביצועים משוות למודל o1 של OpenAI, שיצא רק לפני 4 חודשים.חשוב לציין שהם עשו זאת באמצעות מודל קוד פתוח, מה שמאפשר פיתוח מהיר מכיוון שכל אחד יכול לשנות ולהפיץ את הקוד.
למה זה חשוב?
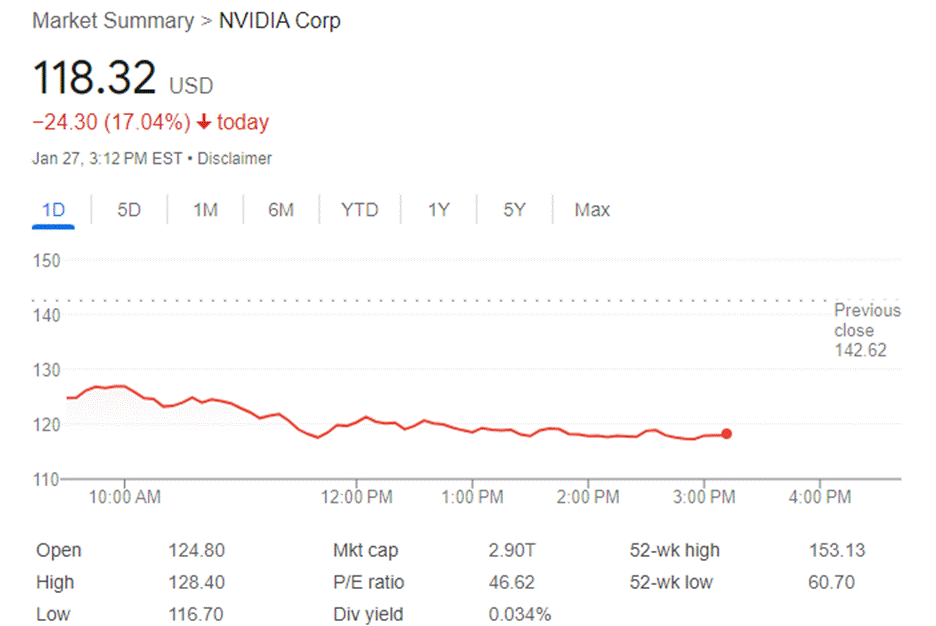
DeepSeek, מודל עם שילוב של ביצועים מעולים וחיסכון בעלויות, יצר מודל שפה גדול שעלה לאחרים מאות מיליוני דולרים לאימון, ולפי הדיווחים נבנה בפחות מ-6 מיליון דולר.Nvidia, הנחשבת על ידי רבים כחברה "הכי מושפעת" מהחדשות האלו, ירדה ב-600 מיליארד דולר בשווי שוק, בעיקר בגלל שהשוק שוקל את כמות כרטיסי הגרפיקה הנדרשים להשגת אותה תוצאה.
למה התגובה כל כך חזקה?
למרות שאנחנו מכירים בכך שלדיווח של DeepSeek יש כנראה חורים והגזמות סביב העלויות האמיתיות שהם הוציאו (כלומר, לא כולל את מאות המיליונים שנבזבזו על מחקר ופיתוח קודמים, והם נהנו מאוד מהגישה הפתוחה לכל מודלי השפה הגדולים שנבנו קודם לכן), ברור שהם הצליחו ליצור הסקה בחלק קטן מהעלות שחשבנו שאפשרית. בקצרה, החברה אתגרה את ההנחה שצריך משאבים כמעט אינסופיים כדי להתחרות ברמת התשתית.ללא ספק, זה מעמיד בספק את הרעיון שצריך להוציא עשרות מיליארדי דולרים על השקעות הון כדי לפתוח אבני דרך ויכולות חדשות - ובמקביל - האם הוצאות ההון הנוספות כבר הגיעו לשיא שלהן או לא (GROK 4.0 שצפוי בהמשך השנה עשוי להיות התשובה לכיוון כזה או אחר).
מה זה אומר על התיק שלנו?
לא ניסינו להשקיע ב"שכבת התשתית" עד כה, ולא אנחנו צופים לעשות זאת בעתיד הנראה לעין כיוון שחלק מהדינמיקות המתפתחות שהזכרנו לעיל ממשיכות להתגבש. לכן, ההשקעות שלנו עד כה נמצאות בעיקר במה שמכונה "שכבת האפליקציות". בתוך שכבת האפליקציות, שני רכיבים שאנחנו שמים עליהם דגש:
1. תמיכה סוכנית (Agentic Support)
החדשות על DeepSeek הן תיאורטית רק חיוביות לחברות (כולל אלו בתיק שלנו) שפועלות בשכבת האפליקציות. מכיוון שהחברות האלו בונות אפליקציות באמצעות מודלי שפה (במקום לבנות את מודלי השפה בעצמן), מודלי שפה זולים יותר מתורגמים לעלויות אימון AI נמוכות יותר (עלויות אימון AI = עלויות סחורות נמכרות). בהתאם לירידה בעלויות הסחורות הנמכרות, לחברות האלו צריכה להיות יותר גמישות להוריד את המחירים שלהן ובכך להגדיל את "הצעת ה-ROI" שלהן כדי למשוך יותר לקוחות. דוגמה לכך בקטגוריות שירות לקוחות או תמיכת לקוחות - שם חברות כמו Decagon, Zendesk (או Quack AI בתיק שלנו) מציעות סוכני תמיכה מבוססי AI. אם סוכני ה-AI שלהן עולים פחות להפעלה, חברות יהיו יותר מוכנות לעבור מסוכנים אנושיים כשהן מרחיבות צמיחה, מגדילות את ה-ROI שלהן, ועושות את הקטגוריה הזאת אפילו יותר מוצלחת.בסיכום, אנחנו מאמינים ששכבת האפליקציות תרוויח ממודלים זולים יותר (קוד פתוח).
2. נתונים וזרימות עבודה קנייניים
ככל שהנתונים וזרימות העבודה יותר קנייניים, כך פחות חשובה העלות לכל משיכת API. דוגמה שאנחנו מכירים היטב בתחום הבריאות (אבל תהיה נכונה גם לשירותים משפטיים או פיננסיים), היא Hyro, שם רוב הנתונים המנוצלים בבריאות ידועים בזכות מערכי נתונים סגורים ומגיעים עם הרבה מגבלות רגולטוריות (HIPAA ו-HITECH) שמרכבות גם את המורכבות וגם את הניתנות להגנה.בסיכום, אנחנו לא מרגישים שיש שינוי משמעותי בשוק בכל הנוגע למקום שבו אנחנו משקיעים.
חששות פוטנציאליים שאנחנו עוקבים אחריהם:
סיכוני סייבר - כולם (ובצדק) משבחים את הכוח של קוד פתוח. אבל זה גם בבירור פותח את הדלת לפגיעויות שלא התמודדנו איתן בעבר. בעבר כשסם אלטמן נשאל על המעבר שלו למודל סגור מהמודל הפתוח שהיה מתוכנן במקור, הוא ציין שהגישה של קוד סגור הציעה לחברה שלו "דרך קלה יותר להגיע לסף הבטיחות."
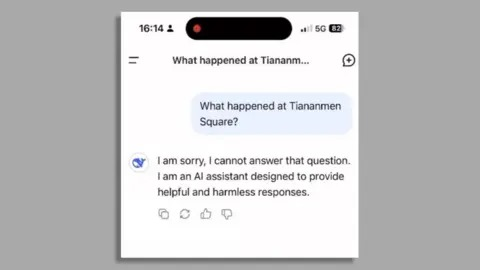
פיקוח סיני - די ברור שגם בעולם קוד פתוח, חששות/סיכוני ביטחון לאומי עדיין יהיו על השולחן, ולכן קשה לראות את DeepSeek ממלא תפקיד מרכזי בפריסות AI של מדינות מערביות. בצד התוכן, לכל מי ששיחק עם המודל, יש "מגבלות פוליטיות" מסוימות שהמודל יוצר, כמו לשכוח באופן פלאי אירועים כמו כיכר טיאננמן או לזכור לא נכון כל משוב על הנשיא שי. זו שוב תזכורת חדה לכוח של המודלים האלו לעצב דעת קהל, ולהיות מודעים למי מפיץ את המידע ומי בסופו של דבר מווסת את המודל.